Introduction
Indie Map is a complete crawl of 2300 of the most active IndieWeb sites as of June 2017, sliced and diced and rolled up in a few useful ways:
- Social graph API and interactive map.
- SQL queryable dataset and example stats.
- Raw crawl data in WARC format: 2300 sites, 5.7M pages, 380GB HTML with microformats2.
Indie Map was announced at IndieWeb Summit 2017. Check out the video of the talk and slide deck for an introduction.
Indie Map is free, open source, and placed into the public domain via the CC0 public domain dedication. Crawled content remains the property of each site's owner and author, and subject to their existing copyrights.
The photo above and on the home page is Map Of The World, by Geralt, reused under CC0.
Indie Map was created by Ryan Barrett. Support Indie Map by donating to the IndieWeb!
Contents
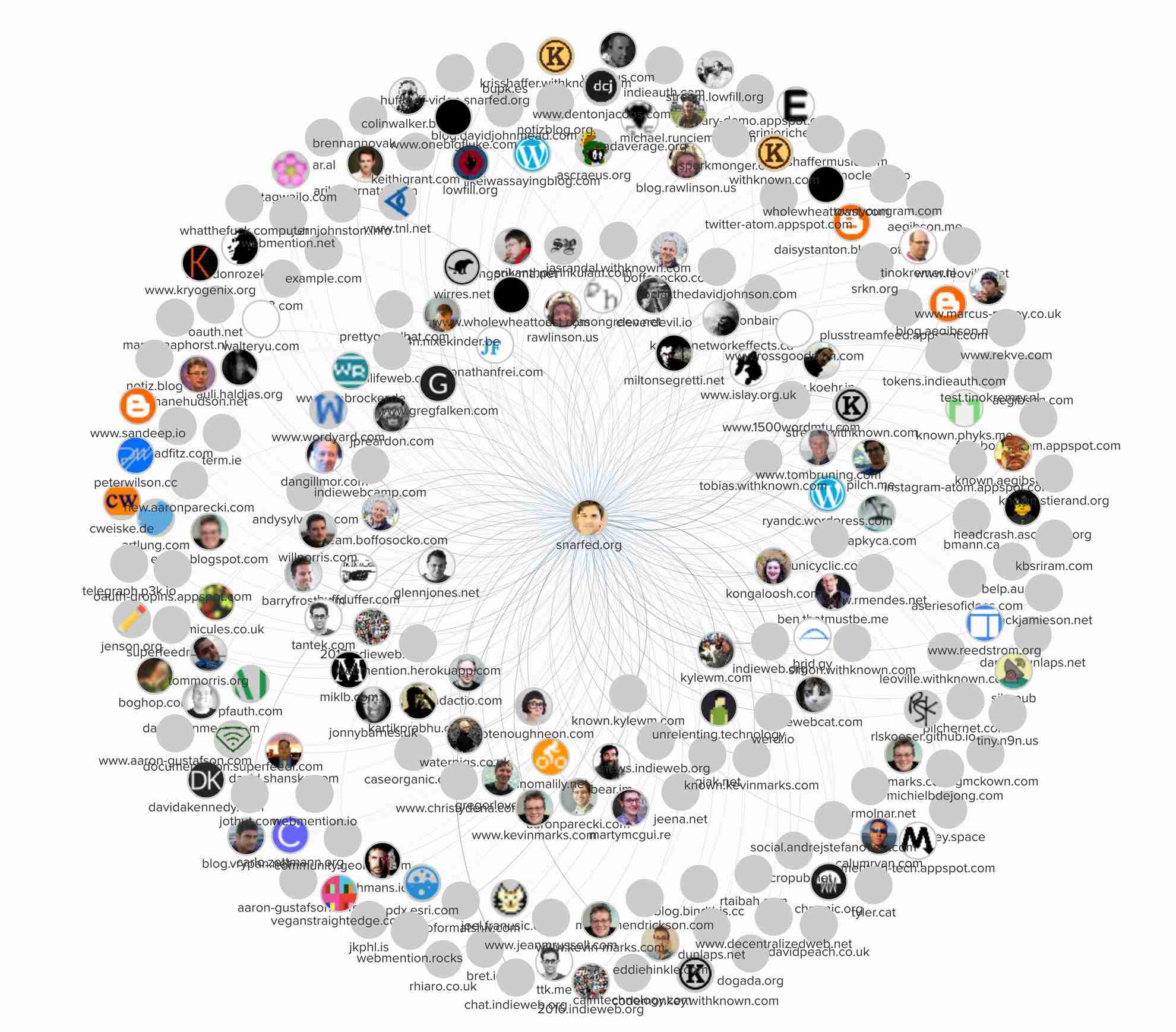
Social graph
Interactive visualization
Click here for an interactive map of the Indie Web social graph, powered by Kumu. It renders all sites and links, by score, and lets you navigate and filter by connections, type, server, microformats2 classes, protocols supported (e.g. Webmention and Micropub), and more.
API
You can fetch each site's data and individual social graph, ie other sites it links to and from, by fetching /DOMAIN.json from this site. For example, my own personal web site is https://indiemap.org/snarfed.org.json. Here's an excerpt:
{
"domain": "snarfed.org",
"urls": ["https://snarfed.org/"],
"names": ["Ryan Barrett"],
"descriptions": ["Ryan Barrett's blog"],
"pictures": ["https://snarfed.org/ryan.jpg"],
"hcard": {...},
"rel_mes": ["https://twitter.com/schnarfed", ...]
"crawl_start": "2017-04-25T10:48:37",
"crawl_end": "2017-04-26T10:56:19",
"num_pages": 6929,
"total_html_size": 169794664,
"servers": ["Apache", "WordPress", "S5"],
"mf2_classes": ["h-feed", "h-card", "h-entry", "h-event", ...]
"endpoints": {
"webmention": ["https://snarfed.org/wp-json/webmention"],
"micropub": ["http://snarfed.org/w/?micropub=endpoint"],
"authorization": ["https://indieauth.com/auth"],
"token": ["https://tokens.indieauth.com/token"],
},
"links_out": 102689,
"links_in": 81519,
"links": {
"indieweb.org": {
"out": {"other": 6750},
"in": {"other": 46800},
"score": 1
},
"kylewm.com": {
"out": {"like-of": 267, "in-reply-to": 172, ...},
"in": {"other": 1041, "invitee": 5, "bookmark-of": 4, ...},
"score": 0.783
},
"werd.io": {
"out": {"in-reply-to": 68, "like-of": 93, "other": 51},
"in": {"other": 602, "in-reply-to": 218},
"score": 0.723
},
...
The hcard field is the representative h-card from the site's home page, extracted by mf2util 0.5.0's representative_hcard().
The links field is a list of other sites with links to and from this site, ordered by score, a calculated estimate of the connection strength. The formula is ln(links) / ln (max links), where links is the total number of links to and from the site, weighted by type, and max links is the highest link count across all sites in this site's list. The weights are:
- outbound: 2x
- inbound: 1x
u-in-reply-to, u-invitee: 5xu-repost-of, u-quotation-of: 3xu-like-of, u-favorite-of, u-bookmark-of: 2x- other or none: 2x
Social network profile URLs are inferred for links to Facebook, Twitter, and Google+ profiles and posts. Those links will appear as e.g. separate objects for twitter.com/schnarfed, twitter.com/indiewebcamp, etc. instead of lumped together in a single twitter.com object. This is best effort only.
The links object is limited to the top 500 linked sites, by score. If there are more, the links_truncated field will be true. You can get the full list of sites by fetching /full/DOMAIN.json. You can also get just the links to/from the sites within this dataset by fetching /indie/DOMAIN.json.
Webmention, Micropub, WebSub, and IndieAuth endpoints are only extracted from the first matching HTML <link> tag, not all, and not from HTTP headers. These bugs may be fixed in the future.
Data
You can download a zip file with the full set of JSON files. You can also look at the individual files in Google Cloud Storage, in the gs://www.indiemap.org bucket. You can access them via the web UI and the gsutil CLI utility, e.g. gsutil cp gs://www.indiemap.org/\*.json . You'll need a Google account, but there's no cost.
Statistics and graphs
Here are a few interesting breakdowns of the data, visualized with Metabase:
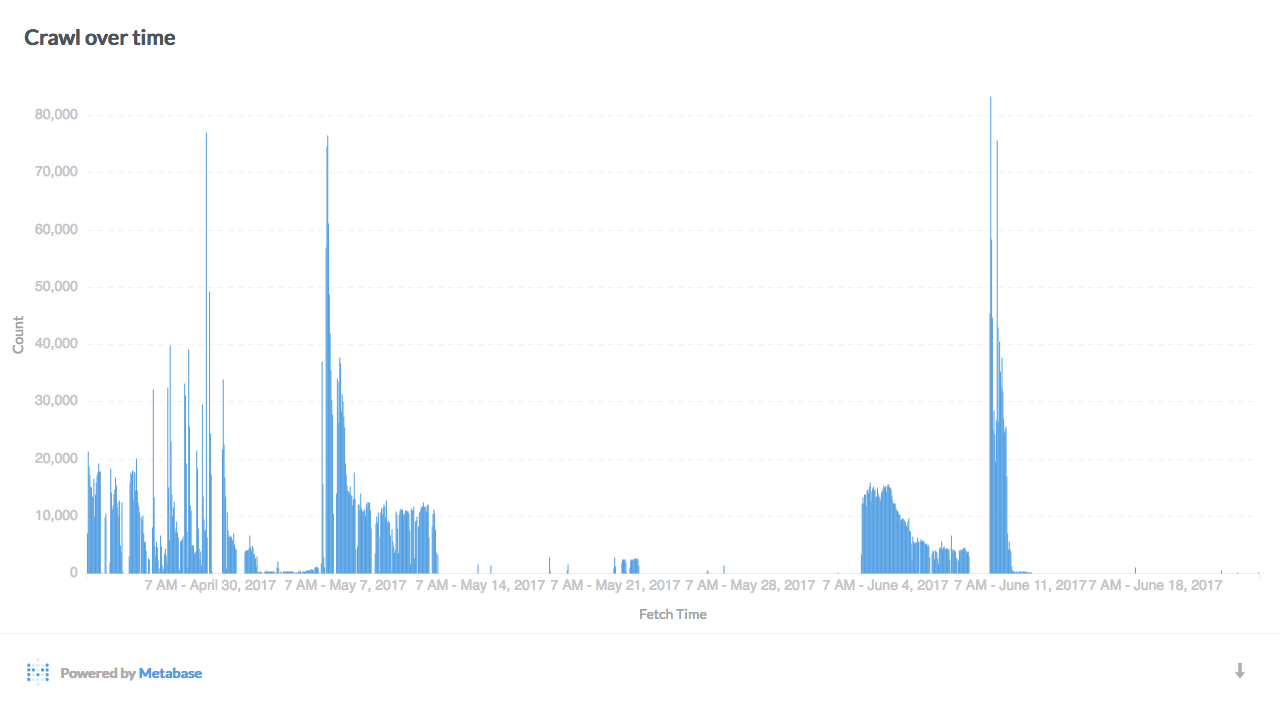
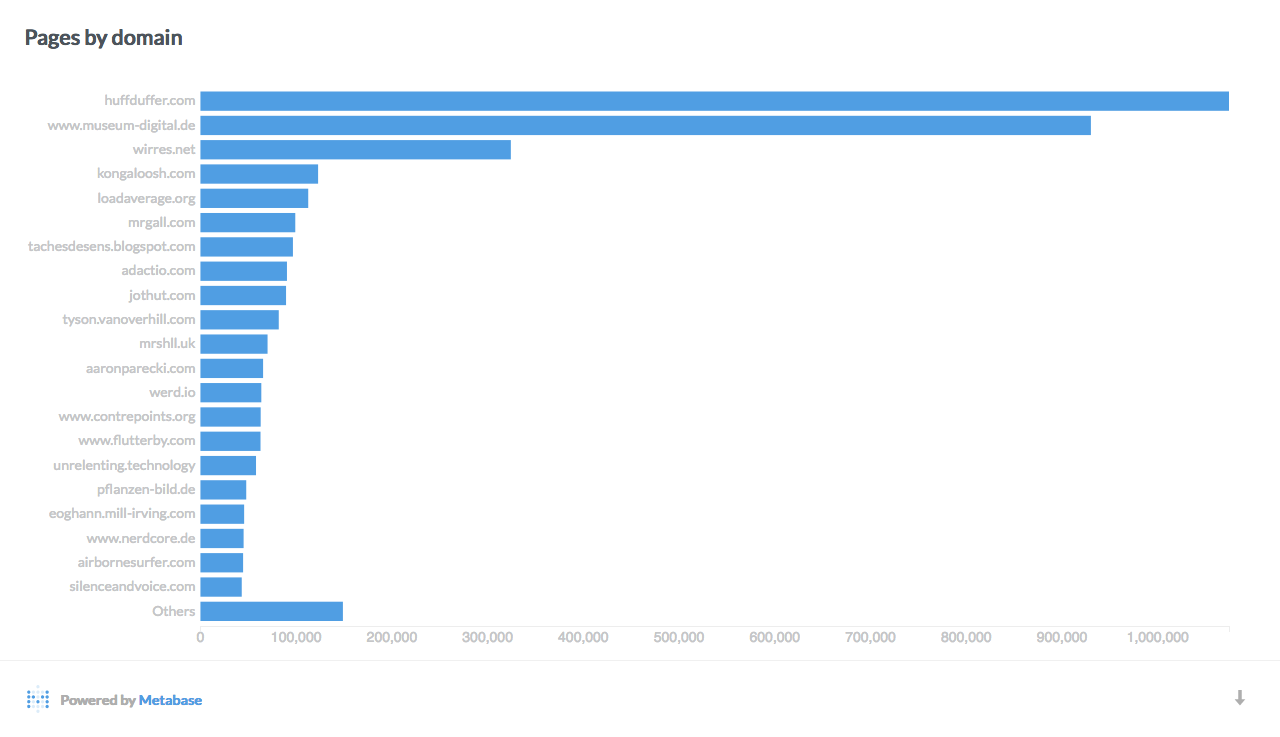
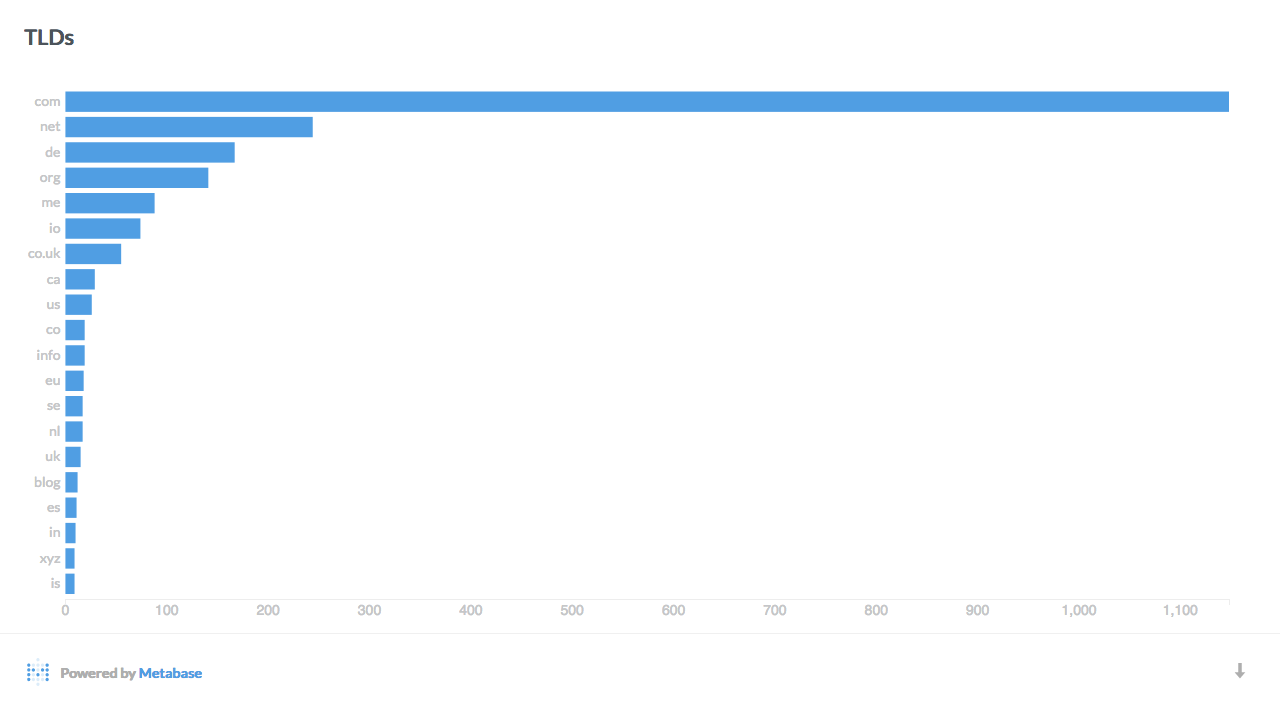
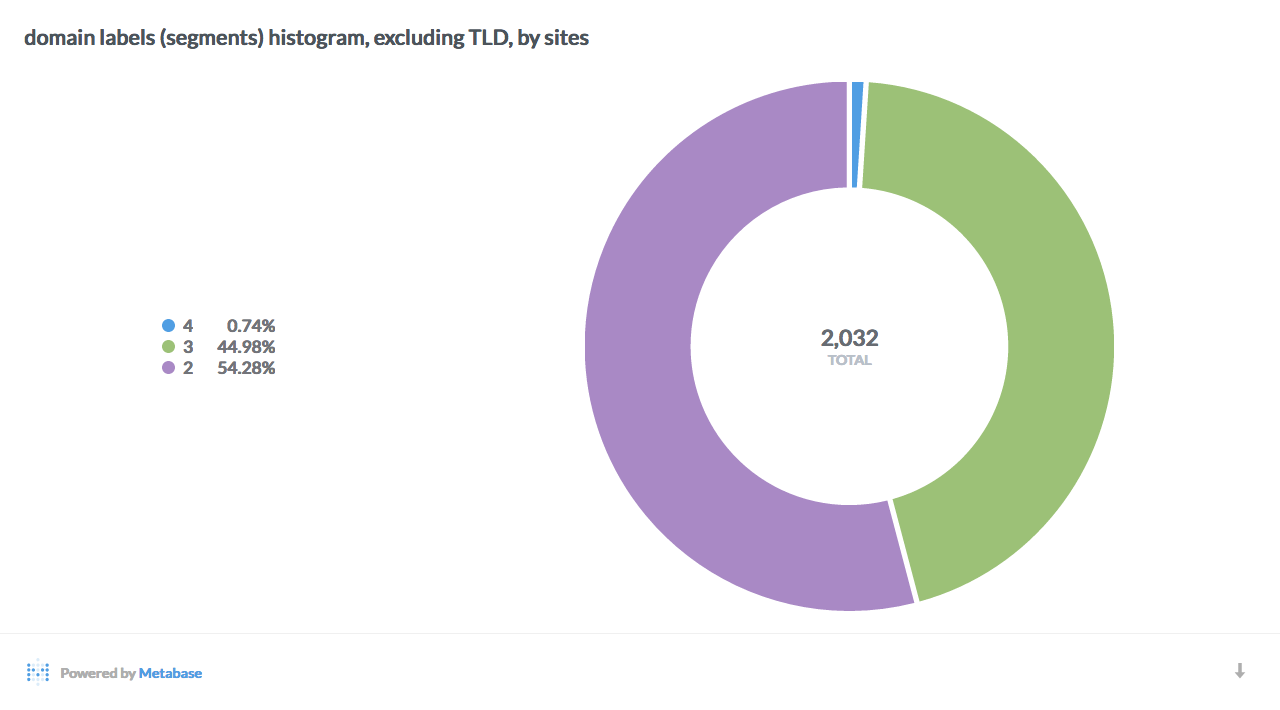
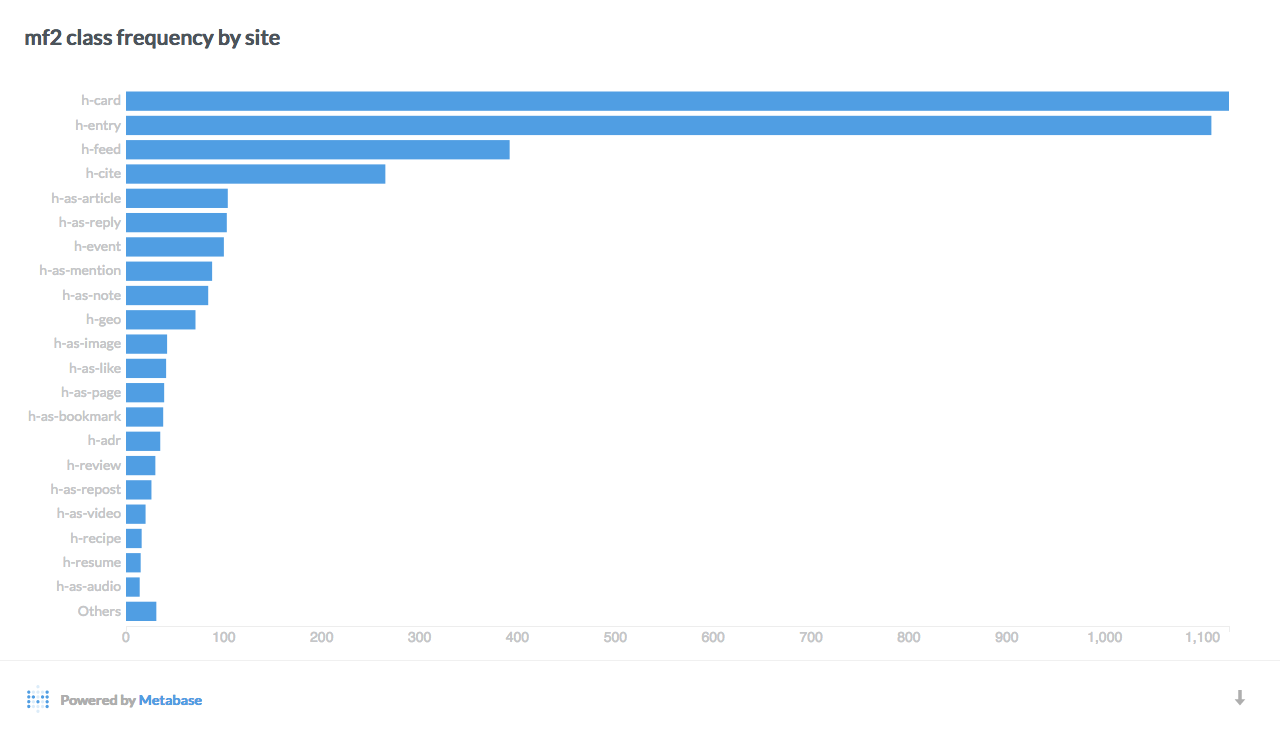
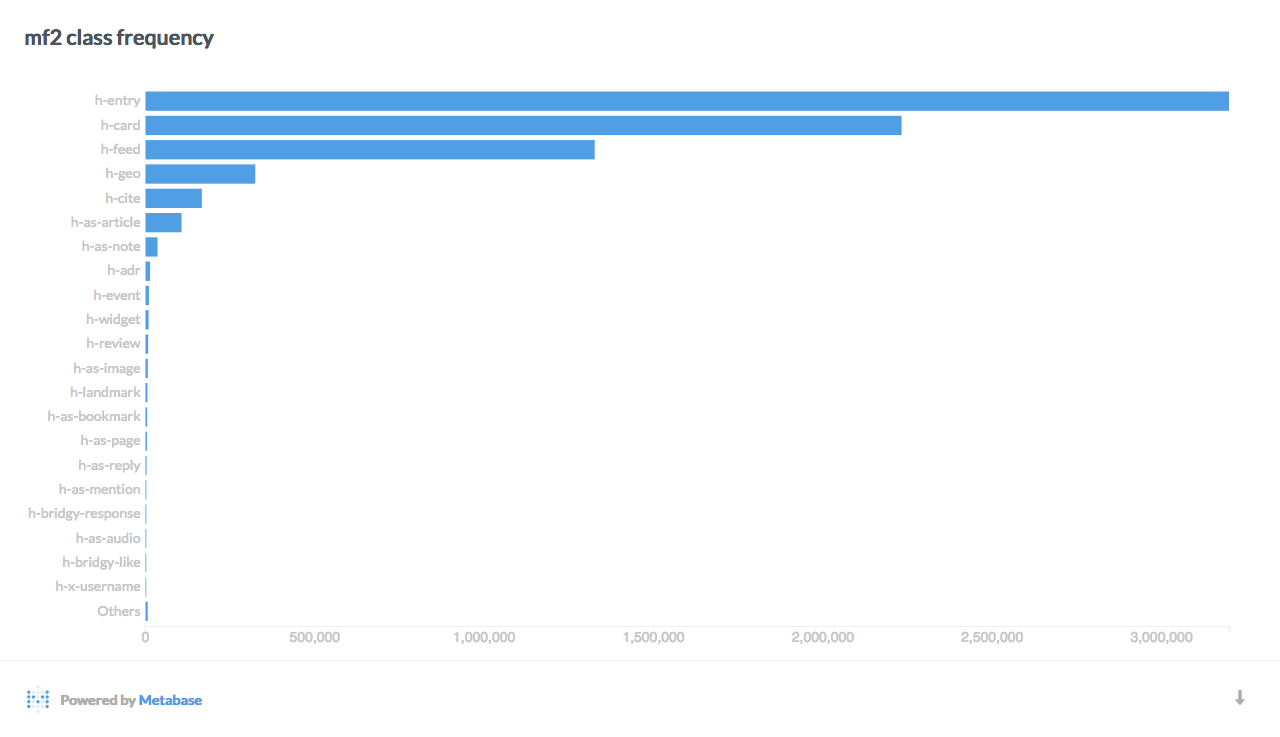

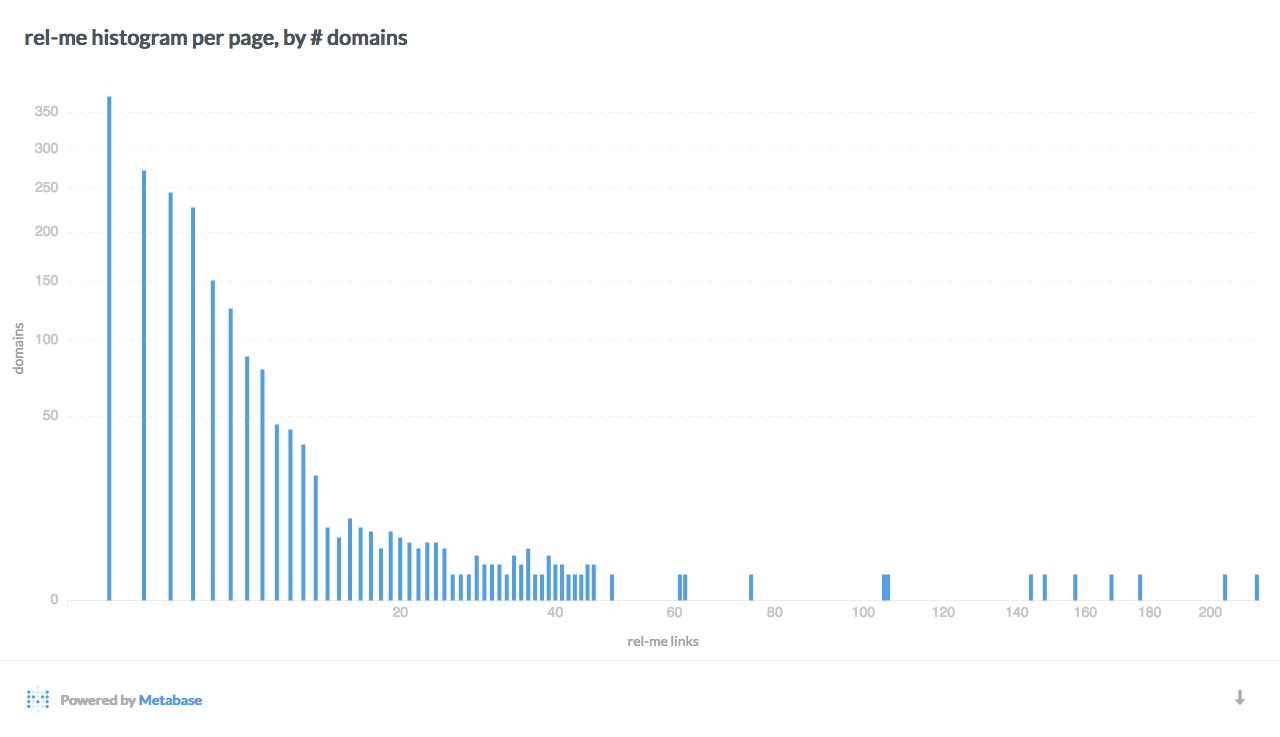
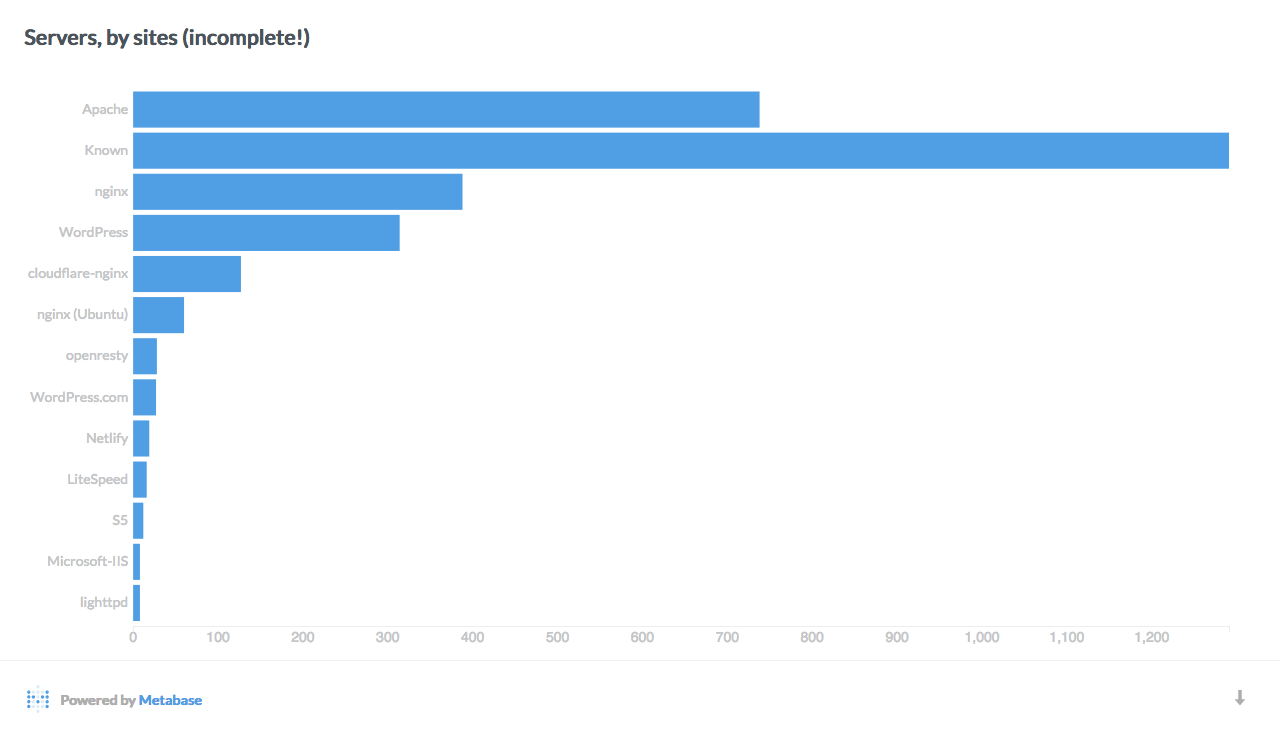
Data mining
The Indie Map dataset is available in Google's BigQuery data warehouse, which supports Standard SQL queries and integrates with many powerful analytics tools. The dataset is indie-map:indiemap. You'll need a Google account. You can query up to 1TB/month for free, but it costs $5/TB after that.
The dataset consists of two tables, pages and sites, and three views, canonical_pages, links, and links_social_graph. Each page's HTML was parsed for mf2 by mf2py 1.0.5, which was then used to populate many fields. Some fields are JSON encoded strings, which you can query in BiqQuery with JSON_EXTRACT and JSONPath.
Example query
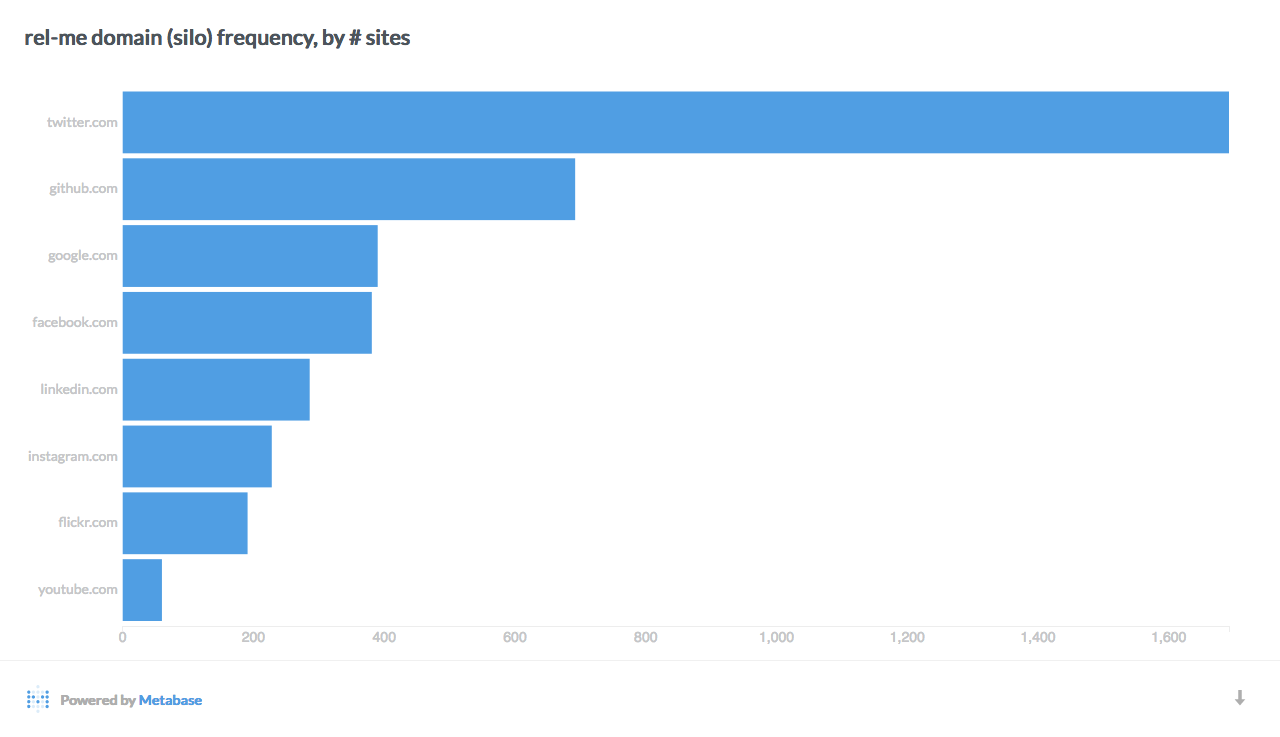
Here's an example BigQuery SQL query that finds the most common rel-me link domains, by number of sites:
SELECT NET.REG_DOMAIN(url) silo, COUNT(DISTINCT domain) sites FROM indiemap.pages p, p.rels r, r.urls url WHERE r.value = 'me' AND NET.REG_DOMAIN(url) IS NOT NULL GROUP BY silo ORDER BY sites DESC LIMIT 15
And here's a Metabase visualization of that query:
pages
All HTML pages crawled, from all sites in the dataset.
| Field name | Type | Description |
|---|---|---|
| url | string | |
| domain | string | |
| fetch_time | timestamp | |
| headers | array< name string, value string > |
All HTTP response headers. |
| html | string | |
| mf2 | string | Full parsed mf2, JSON encoded. |
| links | array< tag string, url string, classes array<string>, rels array<string>, inner_html string > |
All outbound <a> links. |
| mf2_classes | array<string> | All mf2 classes present in the page. |
| rels | array< value string, urls array<string> > |
All links with rel values. |
| u_urls | array<string> | Unique top-level mf2 u-url(s) on the page. |
sites
All sites in the dataset. The names, urls, descriptions, and pictures fields are extracted from the site's home page's representative h-card, HTML title, Open Graph tags, and Twitter card tags.
| Field name | Type | Description |
|---|---|---|
| domain | string | |
| urls | array<string> | This site's home page URL(s). |
| names | array<string> | |
| descriptions | array<string> | |
| pictures | array<string> | |
| hcard | string | Representative h-card for this site's home page, if any. JSON encoded. |
| rel_mes | array<string> | All rel-me links on this site's home page. |
| crawl_start | timestamp | |
| crawl_end | timestamp | |
| num_pages | integer | Total number of pages crawled on this site. |
| links_out | integer | Total number of <a> links in crawled pages on this site to another domain. |
| links_in | integer | Total number of <a> links in crawled pages on other sites to this site. |
| endpoints | array< authorization array<string>, token array<string>, webmention array<string>, micropub array<string>, generator array<string> > |
All discovered URL endpoints in this site's pages for these five link rel values. |
| tags | array<string> | Curated list of tags that describe this site. Possible values: bridgy community elder founder IRC IWS2017 tool webmention.io Known WordPress relme |
| servers | array<string> | List of possible web servers that serve this site. Inferred from the Server HTTP response header, rel-generator links, and meta generator tags. |
| total_html_size | integer | Total size of all crawled pages on this site, in bytes. |
| mf2_classes | array<string> | All mf2 classes observed on pages on this site. |
canonical_pages
A view of pages. Same schema, but only includes canonical pages, ie that don't have a rel-canonical link pointing to a different page.
links
A view of pages. Every <a> link in a page in the dataset, one row per link.
| from_url | string | |
| from_domain | string | |
| to_url | string | |
| to_site | string | |
| mf2_class | string | Possible values: u-in-reply-to u-repost-of u-like-of u-favorite-of u-invitee u-quotation-of u-bookmark-of NULL |
links_social_graph
A view of pages. Counts of <a> links in pages in the dataset, grouped by source and destination domain and mf2 class (or none).
| from_domain | string | |
| to_site | string | |
| mf2_class | string | Possible values: u-in-reply-to u-repost-of u-like-of u-favorite-of u-invitee u-quotation-of u-bookmark-of NULL |
| num | integer | Number of links with the given mf2 class between these two domains. |
Crawl
Data
The raw crawl data is available as a set of WARC files, one per site, which include full HTTP request and response metadata, headers, and raw response bodies. It's also available as JSON files with the same metadata and parsed mf2.
The files are stored in Google Cloud Storage, in the gs://indie-map bucket. You can access them via the web UI and the gsutil CLI utility, e.g. gsutil cp gs://indie-map/crawl/\*.warc.gz or gsutil cp gs://indie-map/bigquery/\*.json.gz. You'll need a Google account, but there's no cost.
Individual pages and sites are timestamped. Indie Map may be extended and updated in the future with new crawls.
Methodology
Sites were crawled with with GNU wget v1.19.1, on Mac OS X 10.11.6 on a mid-2014 MacBook Pro, over a Comcast 100Mbps residential account in San Francisco, between April and June 2017. Notable details:
robots.txtfiles were respected.wget's--recursiveflag was used to follow links.<a>tags were followed.<link>tags were not followed.- Failed requests due to network connections, etc. were retried 5-10 times.
- HTTP requests timed out after 60-120s.
- Most sites were crawled at ~.3 qps to prevent overloading them.
- Most HTTP requests used
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:53.0) Gecko/20100101 Firefox/53.0. Requests for some initial sites usedUser-Agent: Wget/1.19.1. - URLS ending in these file extensions were ignored:
as atom avi bz2 bzip bzip2 css csv doc docx dvf epub exe gif GIF gz GZ gzip ico iso jar jpeg JPEG jpg JPG js json m4a m4b m4v mov mp3 mp4 mpg odt ogg pdf PDF png PNG ppt pptx ps rar rdf rss svg swf SWF tar txt text wav wma wmv xml xls xlsx xpi Z zip. - Other URL patterns were ignored to avoid infinite loop, randomly generated, duplicate, and otherwise low value pages.
wget's--warc-fileflag was used to output WARC files.- Sent
Accept: text/htmlto rhiaro.co.uk for content negotiation, since it returns RDF by default. Otherwise, didn't send theAcceptheader to any other sites.
Full invocation details in wget.sh.
Common Crawl (historical)
I originally tried extracting IndieWeb sites from the Common Crawl, but it turned out to be too incomplete and sparse. Each individual monthly crawl (averaging 2-3B pages) only includes a handful of sites, and only a handful of pages from those sites. They deliberately spread out the URL space, so I would have needed to process all of their crawls, and even then I probably wouldn't get all pages on the sites I care about.
I considered ignoring domains in a blacklist that I know aren't IndieWeb, e.g. facebook.com and twitter.com. Bridgy's blacklist and the Common Crawl's top 500 domains (s3://commoncrawl/crawl-analysis/CC-MAIN-2017-13/stats/part-00000.gz) were good sources. However, in the March 2017 crawl, those top 500 domains comprise just ~505M of the 3B total pages (ie 1/6), which isn't substantial enough to justify the risk of missing anything.
Related:
- Web Data Commons: microformats etc
- Searching for Microformats, RDFa, and Microdata Usage in the Wild
- Social Graph Analysis using Elastic MapReduce and PyPy
- webarchive-commons
Sites included
Any personal web site is IndieWeb in spirit! And many organization and company web sites too. Especially if the owner uses it as some or all of their primary online identity.
For this dataset, I focused on web sites that have interacted with the IndieWeb community in some meaningful way. I tried to include as many of those as I could. The full list is in crawl/2017/domains.txt, which was compiled from:
- People who have logged into the IndieWeb wiki as of 2017-06-09, pulled from indieweb.org/Special:ListUsers.
- Sites webmention.io has successfully sent at least one webmention to, as of 2017-04-29.
- Sites Bridgy has successfully sent at least one webmention to, as of 2017-04-23.
Notable missing collections of sites that I'd love to include:
- All hosted subdomains under withknown.com.
- All hosted subdomains under micro.blog.
I also propose the modest criteria that a site is IndieWeb in a technical plumbing sense if it has either microformats2, a webmention endpoint, or a micropub endpoint. Indie Map doesn't actually use that criteria anywhere, though.
Notable sites
- museum-digital.de: massive digital catalog of over 34k museum artifacts from 84 museums. Includes h-cards and h-geos for many of the artifacts.
- huffduffer.com: over 400k podcast links marked up with mf2.
- contrepoints.org: online French newspaper with h-entrys and h-cards.
- loadaverage.org: fairly big GNU Social instance with mf2. Details.
- wirres.net: large personal site with over 300k pages.
- shkspr.mobi: All of Shakespeare's plays and sonnets, paginated and formatted for mobile.
- indieweb.org, naturally.
- chat.indieweb.org: IRC transcripts from #indieweb[camp], #indieweb-dev, #microformats, and more.
- aaronparecki.com, adactio.com, caseorganic.com, crystalbeasley.com, kevinmarks.com, tantek.com, werd.io: IndieWebCamp founders and elders.
Exceptions
Sites or parts of sites that were excluded from the dataset.- achor.net: huge forum site with mf2.
- adactio.com/extras/talklikeapirate/translate.php: accepts any URL as input, transforms every link in output.
- airbornesurfer.com/gallery/...: massive set of photo galleries generated by Piwigo.
- c2.com/~ward/sudokant.cgi: Sudoku solver CGI app, generates sudoku boards forever.
- chat.indieweb.org: pages for single IRC messages, e.g.
/????-??-??/.... - chriswarbo.net/git/...: web UI to large code repos.
- csarven.ca: requested to be removed on 2018-06-14.
- cyborganthropology.com: MediaWiki special pages, e.g. revision history.
- dentaku.wazong.de: incomplete, but we do have 98k pages!
- dev.subversive.audio/agenda/...: calendar that navigates into the future forever.
- dracos.co.uk/made/bbc-news-archive/tardis/search-headline/...: searchable archive of BBC News headlines.
- fastwonderblog.com/category/.../speaking/consulting/.../: recursive URLs.
- halfanhour.blogspot.com/search: search UI with infinite loop.
- huffduffer.com: incomplete. Crawl only found 330k of estimated 410k items and 8k users. Tag and login pages are omitted.
- indieweb.org: pages for single IRC messages, e.g.
/irc/????-??-??/line/.... - jothut.com/cgi-bin/junco.pl/blogpost/...%5C%22http://toledowinter.com/ (and toledotalk.com): odd recursive URL mirror.
- kinderfilmblog.de/?yr=...,
- kinderfilmblog.de/feed/my-calendar-ics?yr=...,
- kinderfilmblog.de/tolle-kinderfilme/neuerscheinungen-dvd-und-blu-ray/?yr=...: infinite loops.
- kirilind.me/%5C%22/%5C%22/faq/%5C%22/...: infinite loop.
- michael.gorven.za.net/bzr/...: web UI to large code repos.
- nullroute.eu.org/mirrors/shoujoai.com/...: large mirror of another unrelated site.
- thecommandline.net/wiki/...: MediaWiki special pages, e.g. revision history.
- tilde.club/~odwyer/maze/...: random auto-generated maze.
- unrelenting.technology/git/...: web UI to large code repos.
- vasilis.nl/random/daily/.../*.svg: random generated images.
- waterpigs.co.uk/mentions/webmention/?wmtoken=...: infinite loop, with a new token each time.
- webdesign.weisshart.de/suchen.php?...: search results.
- wiki.projectnerdhaus.com: MediaWiki special pages (e.g. revision history) are incomplete.
- www.bakera.de/dokuwiki/...: wiki with lots of query params. Kept actual pages.
- www.barbic.com.au: online shoe store.
- www.downes.ca: a number of CGI pages that consistently 404ed all URLs:
dwiki/?id=...and/cgi-bin/.../*.cgi?... - www.ogok.de:
/search?..., combinatoric explosion of parameter values. - www.rmendes.net/tag/...: incomplete.
- www.xmlab.org/news/blog-post/.../news/blog-post/...: recursive URLs.
External listings
Indie Map is listed in a number of dataset directories and catalogs. Here are a few:
- figshare (DOI: 10.6084/m9.figshare.5160793)
- Kaggle
- datahub
- data.world
- Reddit: /r/datasets
- Awesome Public Datasets